2.Python语法巩固¶
虽然本教程已经默认读者已经掌握了基本的Python语法,但磨刀不误砍柴工,有必要对于常用的Python语法进行回顾,特别是加强面向对象程序设计的意识和思维。
在本章中的例子可能会用到一些Spigot API,但是不了解也无伤大雅,只需理解其中的Python语法即可。
2.1 编码问题¶
在1.1.3中,我们在PySpigot尝试运行了程序。但是如果我们现在把内容换为中文会如何?
1 2 3 4 5 6 7 | |
加载脚本/pyspigot load hello.py后报错:
1 2 | |
在Python 2.7中默认的编码格式是ASCII,所以在未特别说明编码格式时无法正确的使用汉字和其他字符。而Python 3采用UTF-8,则没有这个困扰。所以请开发时特别注意要按照以下形式编写:
- 开头指定编码
#coding: utf-8; - 含或可能含中文时,需要写成形如
u'string'的形式; - print()等Python打印方法中含中文时,一般还需要对字符串进行
.encode('utf-8'),完整为:print(u'你真棒'.encode('utf-8'))。
修改我们先前的脚本,得到:
1 2 3 4 5 6 7 8 | |
重载脚本/pyspigot reload hello.py后正常使用,问题解决。
2.2 变量和运算¶
在变量类型和运算部分,着重提醒学习Python 3的读者几点与Python 2.7的不同。
- Python 2.7中有Python 3没有的长整型变量,在isinstance等判断时需要注意不要忘记可能的"long"类型;
- Python 2.7中str不包括刚才编码问题所提到的加“u”的内容,加“u”后变量类型为unicode,可用它们的基类basestring来判断(但编辑器可能不识别,可用
#type: ignore忽略); - 除法整数除整数只能得到整数,想正常得到结果必须确保其中一个数为浮点数float,但为了以后版本的兼容请不要刻意使用本“特性”。
1 2 3 4 5 6 | |
2.3 条件和循环语句¶
2.3.1 if条件语句¶
在if条件语句中,很多初学者喜欢嵌套if结构。设计一个示例程序:检测是否有玩家在world空手右键在(114, 51, 4)的方块,如果有则打印其名字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
嵌套if在功能上完全不存在任何问题,但是在处理起来仍然不够清晰,阅读起来也不够直观。我们不妨改写为这样的形式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
实际上在很多情况下,if就是一步步排除不合条件的情况的过程,显然后者利用返回来结束执行的写法更加清晰,且更加具有“排除”意味。这种编程模式叫做卫语句(Guard Clause)。在程序设计中,建议读者广泛运用这种编程方式。
2.3.2 for循环语句¶
在for循环使用range()¶
for循环语句常用于遍历可循环对象。Python中的for循环更像MATLAB而非C/C++,无需for(i=0; i<arr.length;i++)通过索引来访问数组等,更加适合其他的可迭代对象,如字典、集合。但有时我们又需要展示序号,这就凸显了range函数的重要性。
比如我们有一个地点名单:['主城', '沃克城', '东篱'],如果单独用for我们只能让其依次打印:
1 2 3 4 5 6 7 8 9 10 | |
但有时我们想按序号排列,除了单独定义一个number变量并在每次循环最后加法外,还可以借助Python的range()函数,创建一个整数列表用于循环(Python 3时这里为一个可迭代对象)。
1 2 3 4 5 6 7 8 9 10 11 | |
下面我们来具体介绍range()的用法:
1 2 | |
在Python 2.7中还存在“xrange()”函数,与Python 3中的range()一致,都是生成迭代器,相较于当前版本的range()可能更节省内存。如有需要请注意未来Python 3版本升级后需要进行的修改。
for循环中的卫语句¶
在for循环中也可以利用continue和break实现卫语句。比如我们设计一个程序,查找当前所有在线玩家中具有“dcr.trust”权限玩家,并返回为列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
2.4 数据结构¶
2.4.1 四种常用数据结构¶
在Python中常用的数据结构有:列表(list)、元组(tuple)、字典(dict)和集合(set)。这些数据类型用于存储和组织多个元素,是 Python 编程中处理数据的基础。在这些数据结构中,又可根据其数据组织形式分为三类:
- 序列类型(Sequence Types):如
list和tuple,用于存储有序的元素集合。 - 集合类型(Set Types):如
set,用于存储无序且不重复的元素集合。 - 映射类型(Mapping Types):如
dict,用于存储键值对(key-value)的集合。
这四种数据结构的用途也各不相同,往往根据需求来确定:
- 使用
list:当你需要一个可变的、有序的元素集合时。类似ArrayList。 - 使用
tuple:当你需要一个不可变的、有序的元素集合时,常用于函数的返回值。 - 使用
set:当你需要一个无序的、不包含重复元素的集合时,适用于去重操作。 - 使用
dict:当你需要通过键快速查找对应值时,适用于构建映射关系。类似HashMap。
这些数据结构是 Python 编程的基石,熟练掌握它们将有助于你更高效地处理和组织数据。其中重点是掌握各种方法,如字典中“in”、“.get()”、“.keys()”、“.items()”的用法。同时也需要掌握“.split()”、“.join()”等字符串与可迭代对象互转方法。
2.4.2 有序字典 OrderedDict¶
如果你有一个键值对想要存储,即需要字典的快速检索,又需要像列表那样有序,那么可以考虑使用OrderedDict。请学习Python 3.7及以上的读者注意,低版本的字典并不有序。
1 2 3 4 5 6 7 8 | |
2.4.3 默认值字典 defaultDict¶
defaultdict 是 dict 的子类,它接受一个工厂函数作为参数,用于为缺失的键提供默认值。它最大的作用是可以自动初始化,从而避免在访问前检查键是否存在的需要,进而简化代码。
1 2 3 4 5 6 7 | |
在上面的示例中,dd['fruits'] 在第一次访问时自动创建了一个空列表。这对于需要为每个键维护一个集合或列表的场景非常有用
2.5 函数¶
对于没有完全理解传参的开发者在前期难免会出现问题,比如对传入的参数使用方法,但发现原值也一同改变。因此,有必要再次强调参数传递的内容。
2.5.1 可变默认参数的陷阱¶
在 Python 中,函数的默认参数值是在函数定义时计算的,而不是在每次调用函数时重新计算。这意味着如果你使用了可变对象(如列表或字典)作为默认参数,并在函数中修改了它,那么这个修改会影响到后续的函数调用。
1 2 3 4 5 6 | |
所以,建议初始值使用None,然后在函数内检测和处理。
1 2 3 4 5 | |
这种做法可以避免默认参数值被共享的问题。
2.5.2 传对象引用的传参机制¶
Python 的参数传递机制是“传对象引用”(也称为“共享传参”)。这意味着函数参数是通过对象的引用传递的,而不是对象的副本。因此:
- 如果传入的是可变对象(如列表、字典),并在函数内部修改了该对象的内容,那么这些修改在函数外部也是可见的。
- 如果在函数内部重新赋值参数名(例如,将列表参数重新赋值为一个新的列表),那么这种重新赋值不会影响到函数外部的变量。
1 2 3 4 5 6 7 | |
在这个例子中,lst.append(1) 修改了原始列表的内容,而 lst = [2, 3] 只是将 lst 重新绑定到一个新的列表对象,不影响 my_list。
2.5.3 默认参数不能依赖于其他参数¶
在前边我们已经提过,在Python中,函数的默认参数值是在函数定义时计算的,而不是在函数调用时。因此,不能在一个参数的默认值中引用另一个参数。同样应该在初始值使用None,然后在函数内检测和处理。
错误示例:
1 2 | |
正确方法:
1 2 3 4 | |
2.5.4 参数类型不受限制¶
与Java等语言不同,Python 是动态类型语言,函数参数不需要声明类型,也不会进行类型检查。这意味着你可以将任何类型的对象作为参数传递给函数。在编程中可以灵活的处理和利用变量。
1 2 3 4 5 | |
但为了使用编辑器的自动补全,建议在编程时尽量将可能的类型注释出来,也能够帮助其他协作者理解。比如我们对上边的函数进行注释:
1 2 3 | |
虽然这种注释在Python 2.7还未引入,但注释只需要给编辑器阅读即可,无需程序执行。请不要使用形如from_: str, to: str的格式,因为Jython还不能识别这种新格式。
在先前我们讲过Python 2.7除了str外还有unicode和basestring,但实际上这种注释是在Python 3下才支持的,因此我们只需要使用Python 3的等位类型即可获得自动补全。
参数类型不受限制的特点,可以配合isinstance()来实现参数转化为我们希望的类型,这在PySpigot程序设计当中十分常用。
1 2 3 4 5 6 7 8 9 | |
2.5.5 善用*args和**kwargs传参¶
在 Python 中,可以使用 *args 和 **kwargs 来接收可变数量的位置参数和关键字参数。
1 2 3 4 5 6 7 8 9 10 | |
在传参时,Python会根据参数个数判断传入的是"arg"还是"*args"。当出现形如"key=value"时,传入kwargs。实际上,直接访问"args"就是一个元组,而"kwargs"就是一个字典。
其中“*”称为“解包运算符”,它可将可迭代对象(如列表、元组、字符串等)解包为单独的元素。这在函数调用、赋值和数据结构合并等场景中非常有用。"**"同样也有类似的用法。
函数调用时解包,将可迭代对象解包为数个参数(最常用)
1 2 3 4 5 | |
变量赋值中的解包
1 2 3 4 5 | |
合并可迭代对象
1 2 3 4 5 | |
2.6 异常处理¶
使用异常处理可以在程序抛出异常时使程序继续运行。捕捉异常可以用“try except”语法。比如在捕捉玩家输入后,判断是否为一个可转为浮点数的字符串(即判断字符串是否是可用的数字)。
1 2 3 4 5 6 7 | |
如果要打印遇到了何种错误,可以进行如下修改:
1 2 3 4 5 6 7 8 | |
在编写程序时,还可以使用“raise”来自主触发异常,从而提醒开发者和终止程序运行,这对于开发库等具有很大的作用。例如某个函数只允许传入字符串:
1 2 3 4 | |
异常处理中还有更多的用法,这里只回顾一些基本的使用场景,读者可参看菜鸟教程或其他资料。
2.7 推导式¶
推导式是一种用简洁语法快速创建可迭代对象(列表、集合、字典)的方式,即“for + 条件判断”自动生成新的可迭代对象。
| 名称 | 结果数据类型 | 基本结构示例 |
|---|---|---|
| 列表推导式 list comprehension | list |
[表达式 for 变量 in 可迭代对象 if 条件] |
| 集合推导式 set comprehension | set |
{表达式 for 变量 in 可迭代对象 if 条件} |
| 字典推导式 dict comprehension | dict |
{键表达式:值表达式 for 变量 in 可迭代对象 if 条件} |
| 生成器表达式 generator expression | generator |
(表达式 for 变量 in 可迭代对象 if 条件) |
其中“if 条件”不需要时可以省略。
2.7.1 列表推导式¶
下面我们来写一个获取全服在线玩家名的推导式
1 2 3 4 5 | |
推导式一行就完成了一般结构需要多行的内容,我们以所有在线OP为例:
1 2 3 4 5 6 | |
2.7.2 字典推导式¶
字典推导式也比较常用,特别是进行一些筛选。比如筛选所有热度超过16的地区:
1 2 | |
对于其中的“k: v”也可以灵活的修改和运用,比如获得一个“地区名: 地区名字数”的字典:
1 2 | |
2.7.3 集合推导式¶
集合推导式与字典推导式长相类似,都使用“{}”,但是集合推导式没有“key: value”的形式。比如对列表内的元素去重并平方:
1 2 | |
有时也会对字典使用集合推导式,但根据目的可能会采用“.items()”或“.keys()”方法。比如获取热度超过16的地区名集合:
1 2 | |
内容补充:
类似列表推导式这样一行解决问题的还有“条件表达式”,也叫“三元表达式”,其格式为“A if condition else B”。若条件成立返回A,不成立则B。
2.8 常用内置函数¶
内置函数在Python 2.7中具有重大作用,这里只挑选几个常用且关键的函数,更多内容可参看菜鸟教程或其他资料。
2.8.1 all()¶
all()函数用于判断可迭代对象中所有元素是否都满足条件。比如在开发DC邮电寄递系统时,物品输入是以元素为ItemStack的列表来实现的。当实现检查是否为空的功能时,不仅要考虑到列表是否无元素,还要考虑到getContents可能返回的元素均为None的空列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
all()接受传入一个可迭代对象,判断其中是否所有元素都为True,即判断是否所有元素都并非0、None、False。上边的例子就是传入了一个生成器表达式,依次取出每个元素x去判断“x is None”,返回True和False,整体来看就当x全为None时则返回True。
与之对立的是any(),用以判断可迭代对象是否全部为False,可类似的进行使用。
2.8.2 isinstance()¶
isinstance()用以判断一个对象是否是一个(些)类或这个(些)类的继承类。
1 | |
在2.5.4中我们已经示范了一般用法,如果面对判断是否为一种数字的情况,就可以在第二个参数传入一个元组:
1 2 | |
2.8.3 max()和min()¶
man()和min()顾名思义,返回给定参数的最大和最小值。这里以max()举例。
最简单的用法就是判断一些数的最大值:
1 | |
max()同样支持输入一个生成器表达式。下边的例子用于获取列表lst中最长的字符串:
1 2 | |
还可以找到列表中元素满足key表达式的最大值,比如处理下边两个字典“arrTime”中最大值:
1 2 3 | |
2.8.4 sorted()¶
sorted()的作用是对可迭代对象排序,返回一个新的排序后的列表。与列表的.sort()方法不同,sorted()是新生成一个列表,不会修改原列表的数据。
1 2 3 4 | |
还是写一个类似2.8.3的字符串的例子:
1 2 3 | |
很多熟悉、了解数据结构的编程能手喜欢自己写一个“高端”的排序算法,但是绝大多数情况下直接用Python为我们提供的sorted()才是最高效率的,因为sorted()函数的背后是直接用解释器的语言编写的高效算法,自己在Python实现的算法不可能比它还快。除非编程者在打算法比赛,或者确有不常见需求,否则请不要自行实现其他方法。
2.9 面向对象的程序设计¶
Python是一门面向对象的语言,鉴于PySpigot是运行在Java和Spigot的基础上,掌握面向对象的编程方法就更为重要。如果先前已经具体学习过面向对象的语言,那么Python在编程思路上基本上与它一致,只需要注意语言之间表达的不同形式。
2.9.1 类与对象¶
定义类¶
类(Class)是一种抽象,是同一类对象的共同属性和行为进行概括。将抽象出的数据、代码封装在一起,形成类。可以理解为类是一种模板。
定义类的基本格式:
1 2 3 4 5 6 7 8 | |
其中“object”代表是“新类”,只有“新类”才具有继承的功能。而Python 3中默认是新类。建议在编程时都使用新类。
需要特别注意,类中的“函数”都是“方法”(method)。在PySpigot内建的功能中,二者具有严格的区分,在要求函数(function)时输入方法的话会无法运行,因此请使用lambda来修饰。
内容补充:
lambda是用来创建匿名函数的语法,其格式为:lambda 参数列表 : 表达式,常用于这类小函数。在2.8.3中就有这样的例子。
类成员的访问控制¶
- 公有类型成员:类与外部的接口,任何外部函数都可以访问公有类型数据和函数
- 私有类型成员:只允许本类中访问,外部任何函数都不能访问
- 保护类型成员:只允许本类和其派生类允许访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
构造函数¶
类在初始化成对象时,是通过构造函数进行的。构造函数即为“__init__”,其传参等与函数一致。比如设计了一个个人信息类:
1 2 3 4 5 6 7 8 9 10 11 | |
不定义任何构造函数时则使用默认构造函数,是没有参数的构造函数。
对象¶
对象是类的实例(Instance),由类通过构造函数变为对象是完成了实例化。比如对Profile进行构造,并赋给profile变量:
1 2 | |
2.9.2 类的继承¶
类的派生和继承体现了事物普遍联系的观点。现实世界的事物既作为个体存在,同时也作为联系中的事物存在。人们在认识世界的过程中,根据事物所具有的普遍性和特殊性、共性和个性,利用分类等科学方法对其分析和描述。比如,汽车、火车、飞机、轮船等都属于载具,而汽车、火车、飞机、轮船又各有不同的种类。为了减少代码重复程度,便于功能的复用和扩展,我们使用类的继承,使派生类(子类)拥有基类(父类)的属性和方法。
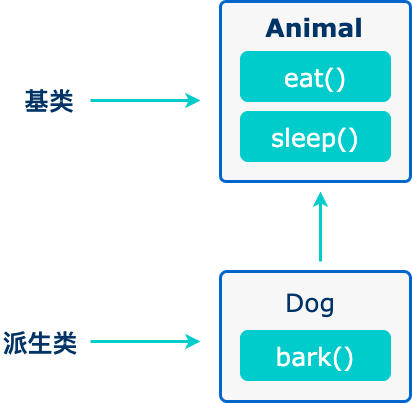
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
在Paper API中,也具备这样的开发思路。我们以Inventory为例:在Minecraft中很多的对象(包括生物、方块)都具有容器,但其大小、形式、功能也不同,并且容器的持有者又有不同的功能,如果每个都单独开发势必会使工作量陡增,同时降低其“互换性”。在Paper API中,通过这样的设计来解决这个问题:
对于不同的容器,都是Inventory的派生,使用isinstance(obj, Inventory)全部返回True。
graph LR
A[Inventory]-->AA[AbstractHorseInventory]-->AAA[HorseInventory]
AA-->AAB[LlamaInventory]
A-->AB[AnvilInventory]
A-->AC[DoubleChestInventory]
A-->AD[CraftingInventory]
A-->AE[FurnaceInventory]
A-->AF[PlayerInventory] 对于不同的容器持有者,都是InventoryHolder的派生。
graph LR
A[InventoryHolder]-->B[AbstractHorse]
A-->C[Container]
C-->Barrel
C-->Chest
C-->Furnace
C-->ShulkerBox
A-->Jukebox
A-->Player
A-->Piglin
A-->D[ChestBoat]
D-->OakChestBoat
D-->SpruceChestBoat 这些InventoryHolder的派生类除了是容器以外,还各自分属于不同的类,即派生类可以继承多个基类。我们以大家最熟悉的Player为例:
graph LR
Attributable-->D
AnimalTamer-->D
Damageable-->D
C[Entity]-->D[HumanEntity]-->B[Player]
InventoryHolder-->D
C-->LivingEntity-->D
CommandSender-->C
Nameable-->C
Permissible-->C
ServerOperator-->C
OfflinePlayer-->B
ProjectileSource-->D 但是在Python 2.7中,多继承可能会遇到除第一个外后边方法无法直接使用的问题,这时可能就需要手动在派生类添加一个方法。
2.9.3 多态性¶
多态性即为方法名相同,但在不同类的表现不同,也可以叫做“方法重写”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
这里的Animal类似就类似我们上边介绍的Abstruct类,由于speak功能及其依赖于动物的不同类型,只能预留好这个方法,在派生类开发。这里就用到了前边的异常处理,主动发起了一个NotImplementedError(未实现错误),来提醒继承你开发的基类的开发者有方法未实现。在各自派生类中,由于重写了speak方法,所以可以正确的运行,这就是多态性的体现。有了Abstruct类,就可以更方便的使用isinstance()来判断是否为某一类。
当然,不继承Animal也是可以的,只要都有speak方法即可。这种基于接口的调用,就是典型的鸭子类型(Duck Typing):“如果它走路像鸭子,叫声像鸭子,那它就是鸭子。”
2.9.4 析构函数¶
析构函数是在类的对象生命周期终止时所运行的函数。一般不需要编写析构函数,仅有特殊需求时使用。
例如Util2中有一个ConfigUtil,是关于配置文件的工具。配置文件的MemorySection需要使用“save()”才能写入文档,那么我们可以使用析构函数来在生命周期结束前进行保存。
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
2.9.5 运算符重载¶
运算符重载使自定义类与Python运算符(如+、-、*)进行交互,且表现出自定义行为。背后是通过一系列的特殊方法来实现的:
| 运算符 | 方法名 |
|---|---|
+ |
__add__ |
- |
__sub__ |
* |
__mul__ |
/ |
__truediv__ |
// |
__floordiv__ |
% |
__mod__ |
** |
__pow__ |
== |
__eq__ |
< |
__lt__ |
> |
__gt__ |
例如我们编写一个二维向量类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
当然,这不是必须的,使用对象方法也依然优雅。
章节练习¶
请使用面向对象的程序设计方法,设计一个满足下述要求的查询列车时刻的程序,示例列车时刻表已给出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
- 至少需要实现的功能:
- 能够正确将时刻表中时间整理为到点和发点,并计算站间历时和总历时;
- 查询并展示站到站的所有可用列车,并按历时进行升序排序,且需展示车站是否为始发、终到站;
- 展示指定车次的所有停站,显示总历时和各站到点、开点;
- 展示指定车站的所有列车,显示车次和在车站的开点;
- 展示时需尽量进行对齐。
- 供参考的开发提示:
- 编写一个专门用于处理列车每个停靠车站信息(车站名称、到发时)的类,在这个类中实现将时刻分个处理为到发时等方法;
- 编写一个处理列车信息的类(车次、开行频率、所有车站),负责将给出的时刻表进行处理,并实现获取全程历时、某站是否为始发(终到)站判断等方法;
- 按需要编写其他代码。
- 程序设计要求:
- 必须使用面向对象的程序设计方法;
- 对于字符串处理、排序等,已有内建方法的不要自行“造轮子”;
- 使用
#type:标记函数和方法的参数类型、返回值类型等信息; - 具有可读性较高的注释;
- 不要求一定在PySpigot上运行(即不要求现在就学会调用相关API),也可以在CPython上运行,由开发者自行决定环境,但必须使用Python 2.7的语法;
- 有余力者,可在“至少需要实现的功能”基础上,完成一些实用的自定义功能;
- 不得试图使用任何人工智能手段生成整段代码,不推荐使用内置激活的人工智能功能的编辑器或IDE;
- 满足其它提及的要求。
- 练习完成后提交时,请将源代码、运行结果截图一并提交。